Consistent Hashing And Load Balancing
Introduction
The topic of this blog is one of the fundamental concepts of System Design. If you want to design a fault-tolerant distributed system you should be aware of load balancing and consistent hashing. We will explore the following topics in this blog.
- What is Load balancing?
- What is hashing?
- Problem with using traditional hashing with Load balancing
- Consistent hashing
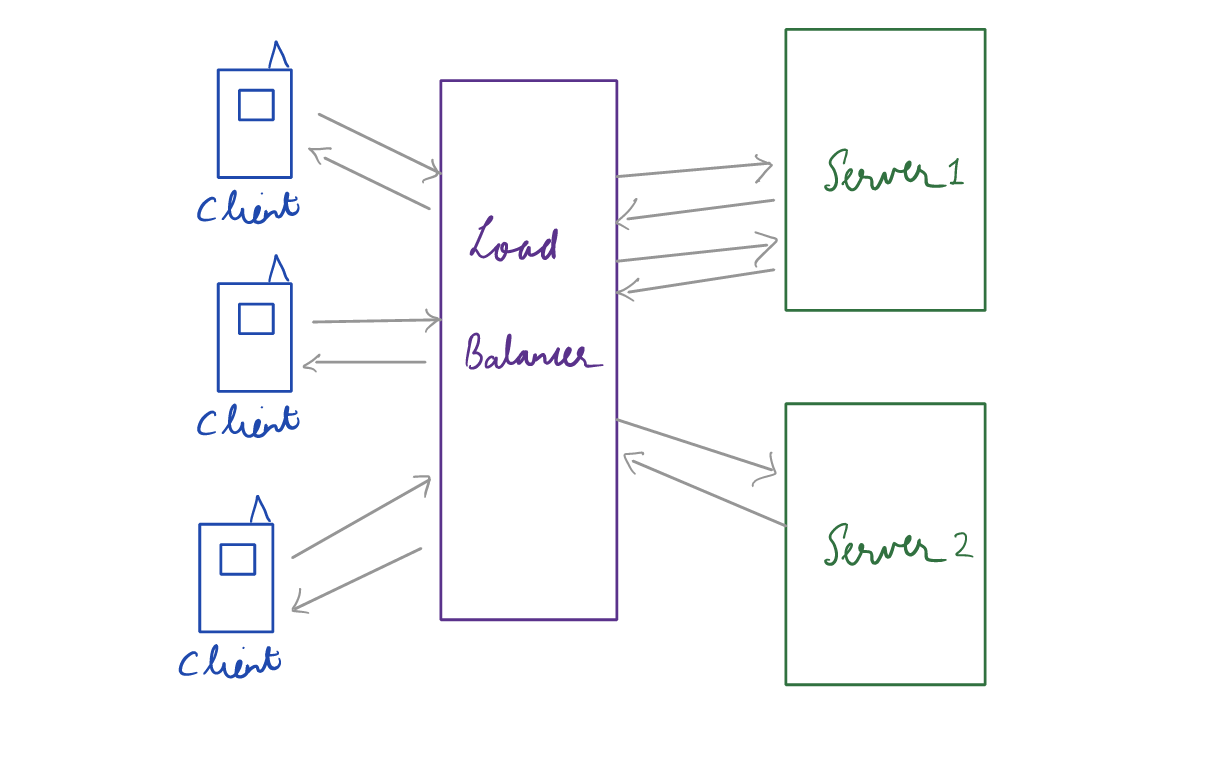
What is Load Balancing?
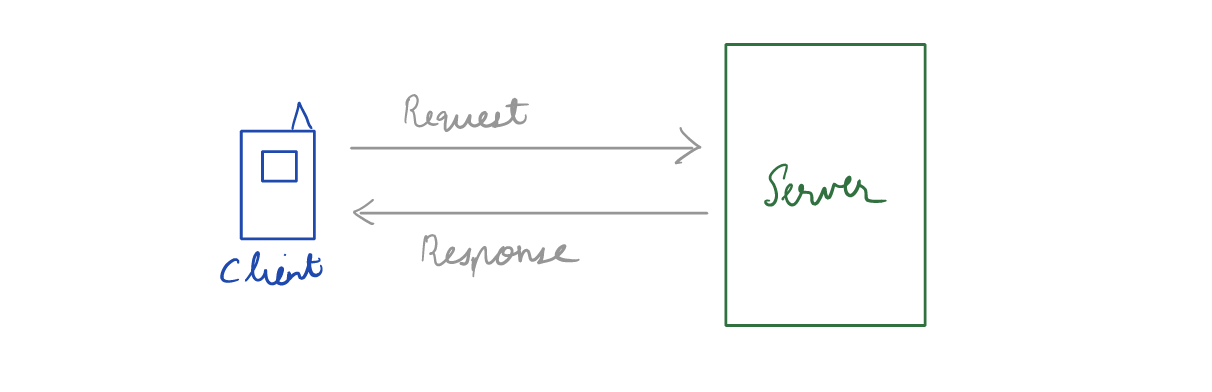
Suppose you have written an image recognition algorithm that detects from a picture whether there is a dog or a cat. You would like to share your algorithm with other people in order for them to consume it. You would set up a machine that would run your algorithm which is available 24/7. This machine is called a server. The person who wants to classify the image will use your API to communicate with the server. This is called a client.
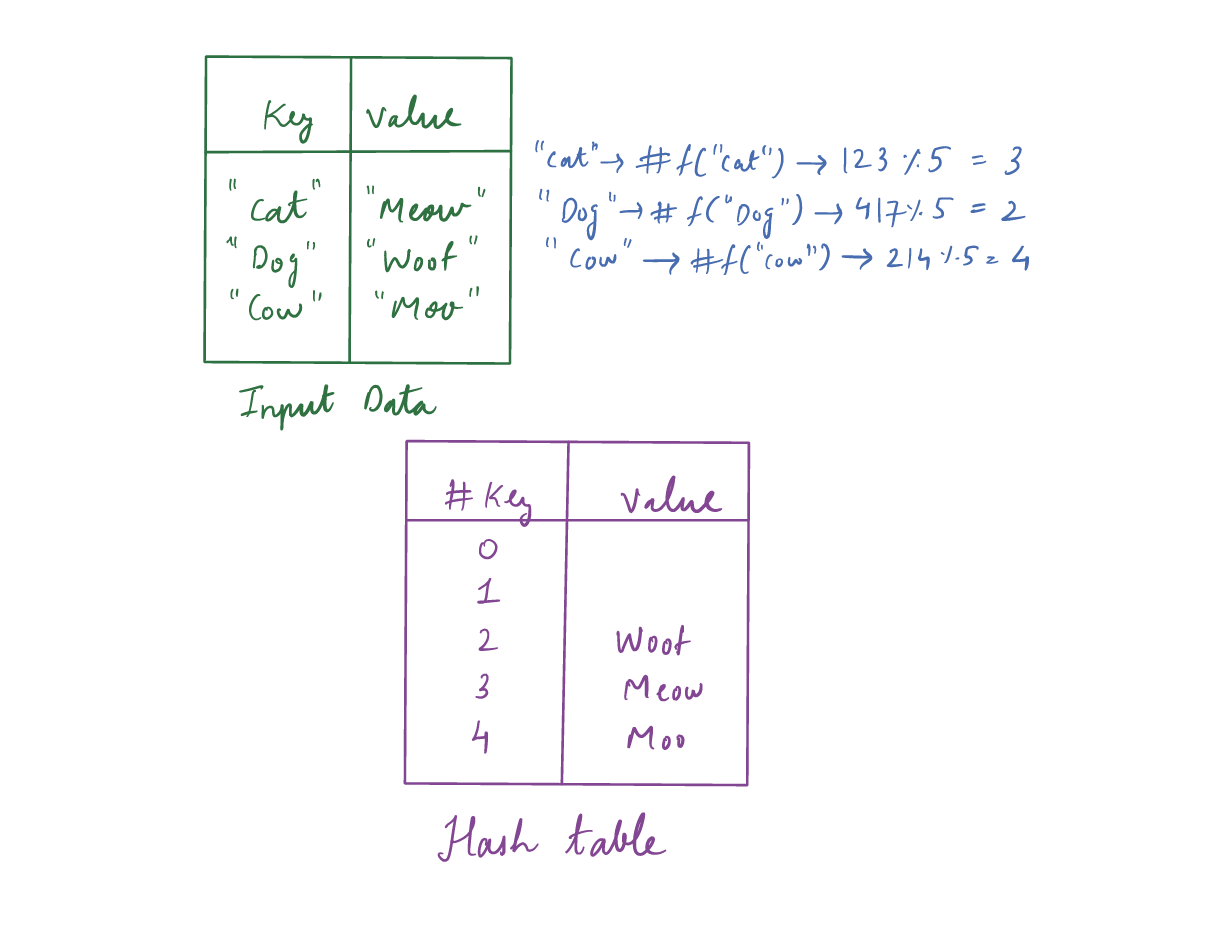
What is Hashing?
Hashing is basically storing a key-value pair. We use a hash function which we apply to the key that generates a new address and the value of that key is stored at that address. While retrieving the value for a key we use the same hash function and get the value stored at the memory address. The whole process of retrieving a value in the hash table is constant time O(1) operation. Below is a basic example of how values are stored with the hash function. We have 5 memory space available from 0-4. We apply the hash function to the key and apply modulo operation to map every key’s hash value from 0-4.
Problem with using traditional hashing with load balancing
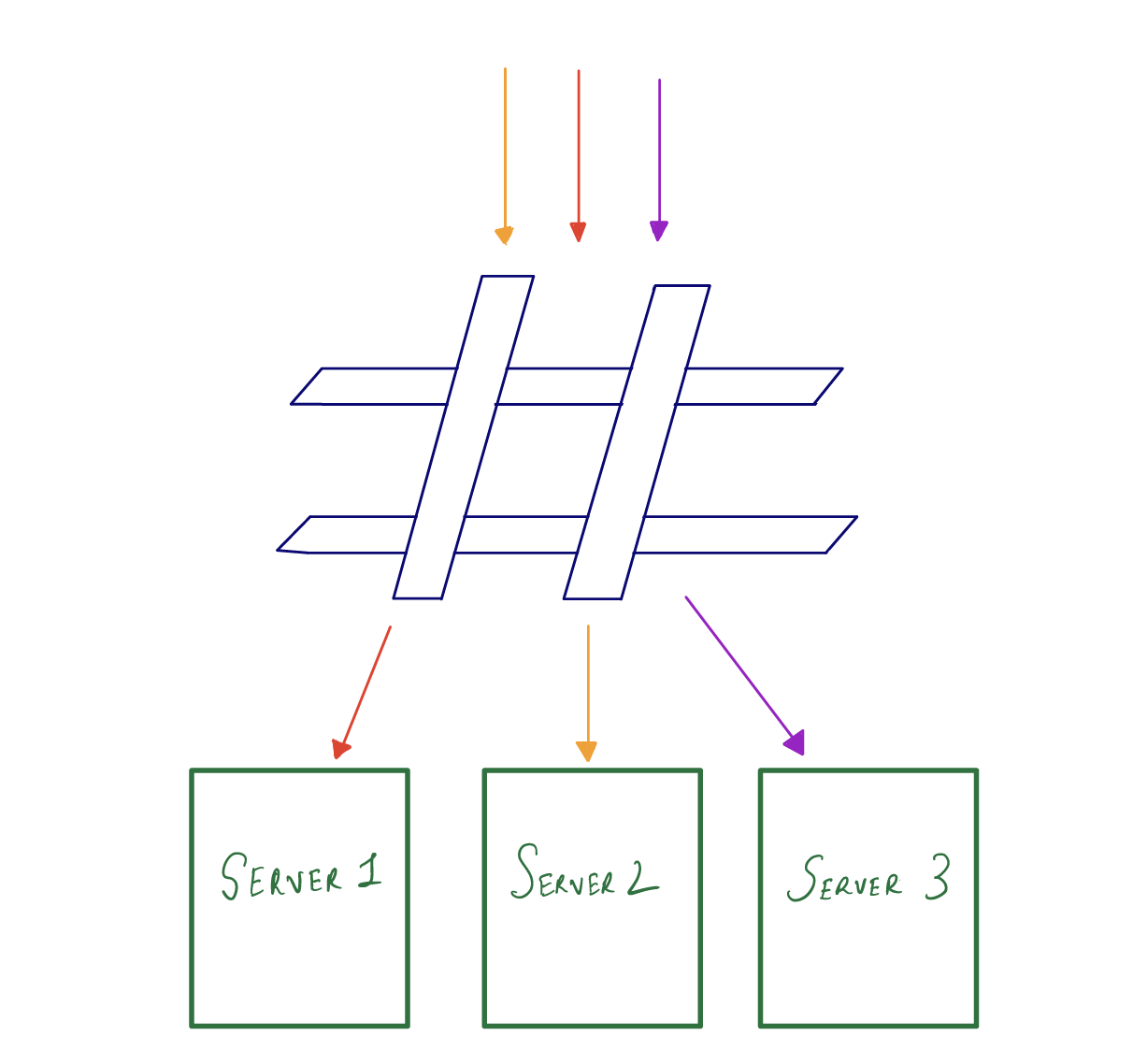
The load balancer keeps track of which request is sent to which server by using the hash table. We do this because we want to send a similar request in the future to be redirected to the same server this will make the response faster since we can use the already cached response.
Suppose we have 4 servers and so by using the traditional hashing we will apply the hash function to the request Id and modulo it by 4 (number of servers) to map it to the particular server. An example is shown below.
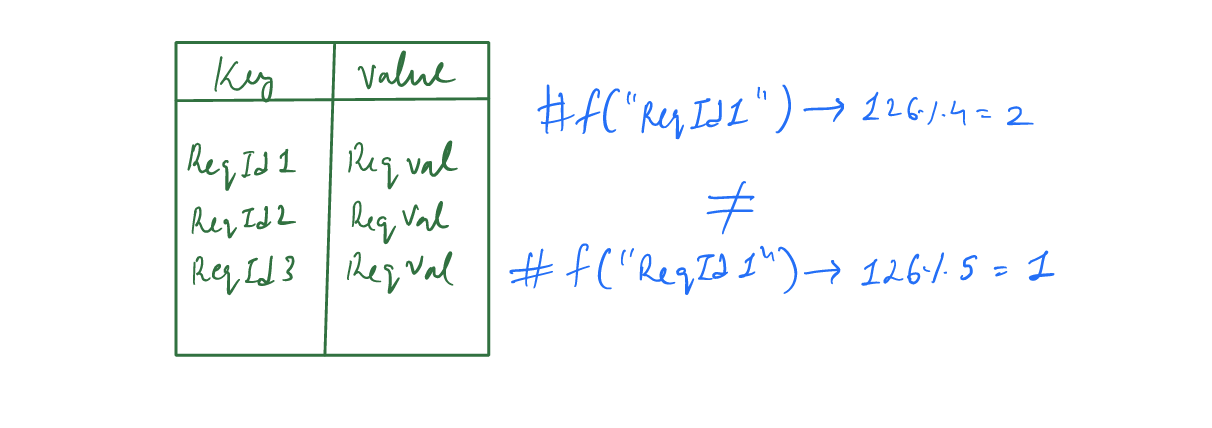
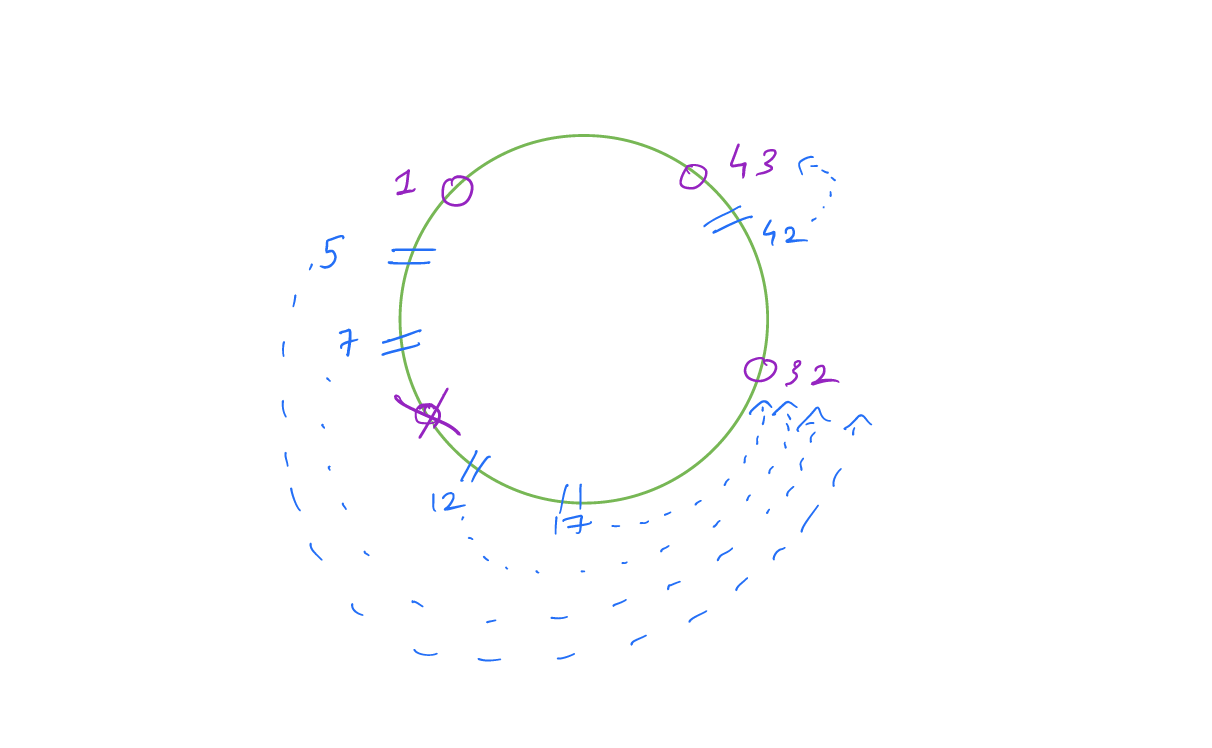
Now instead of performing modulo by 4, we do modulo by 5. Thus the previous request needs to be re-routed to a new location. We lose all the useful information of caches already saved in other servers since now the new request is sent to a different server.
This problem is solved by using consistent hashing.
Consistent Hashing
The basic idea of consistent hashing is to map the servers and the request to the same Id space. Let’s take an example to better understand this concept.
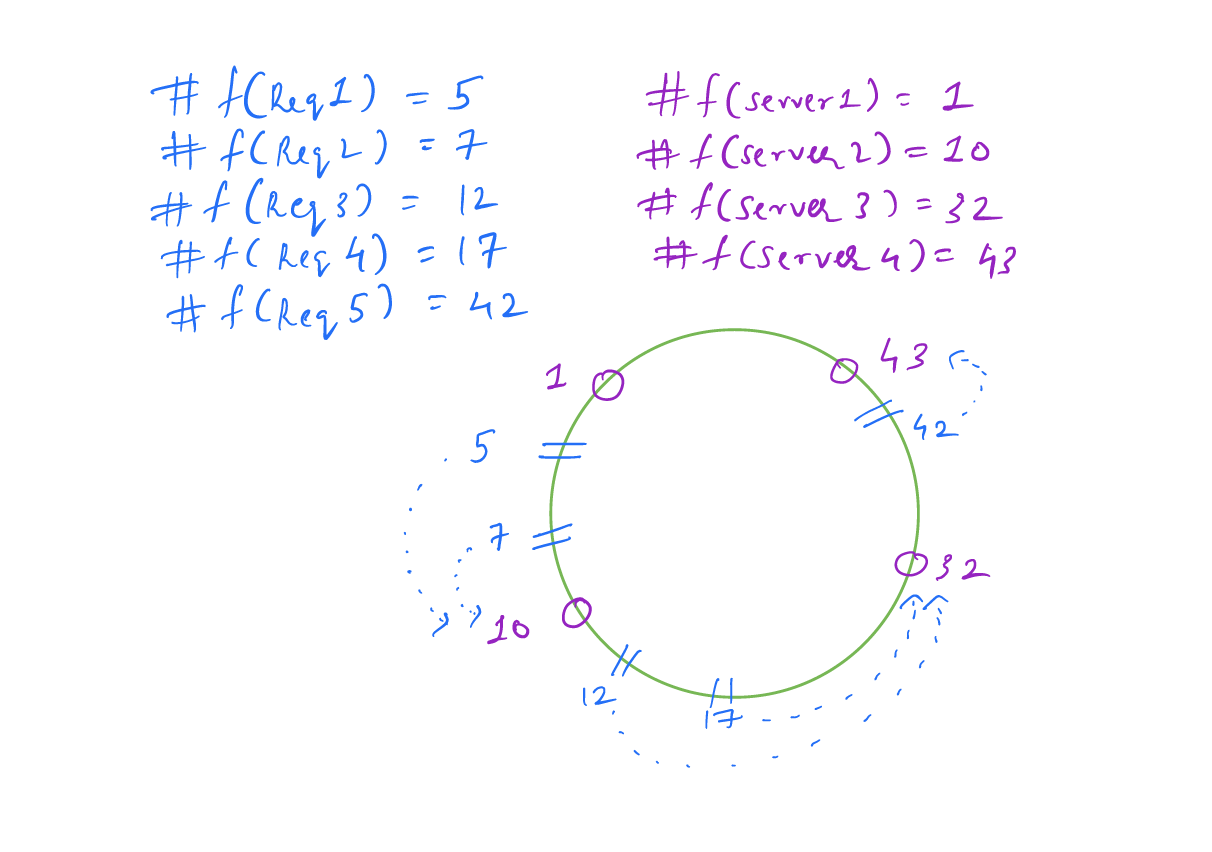
Suppose we have 4 servers. When passed through a hashing function map to ids 1,10,32,43.
We get multiple requests. We pass the request through the same hashing function and it maps to ids 5,7,12,17,42
Instead of imagining a hash table ids as a linear row consider it as a ring. The diagram of the hash ring is shown below. The requests are mapped to the successor server ids.