Deep dive into B and B+ Trees and how they are useful for indexing in database

Introduction
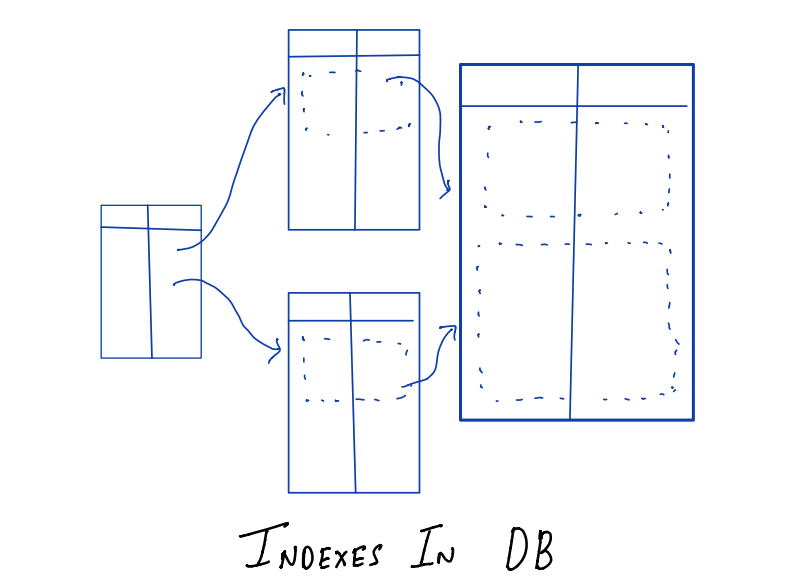
The aim of this post is to explain B and B+ tree data structure and how they are connected with indexes in the database. They are useful for reducing the time for executing a query within a database by making data retrieval faster.
We will go through the following topics for understanding this concept.
- M-way search tree
- Data representation of M-way search tree
- B trees
- B+ trees
If you like the following article please subscribe to the blog, to receive notification of newer posts.
M-Way Search Tree
Most of us are familiar with the concepts of a binary search tree, where each node has 1 key and at most 2 children per node. Keys in the left subtree are smaller than the keys on the right subtree. If the tree node has at most 3 children it’s called a 3-way search tree, 4 children then it’s called 4-way search tree and so on. In general, if the node in the tree has m number of children then it’s called an M-way search tree. Below is a visual example of BST and 3 way search tree.
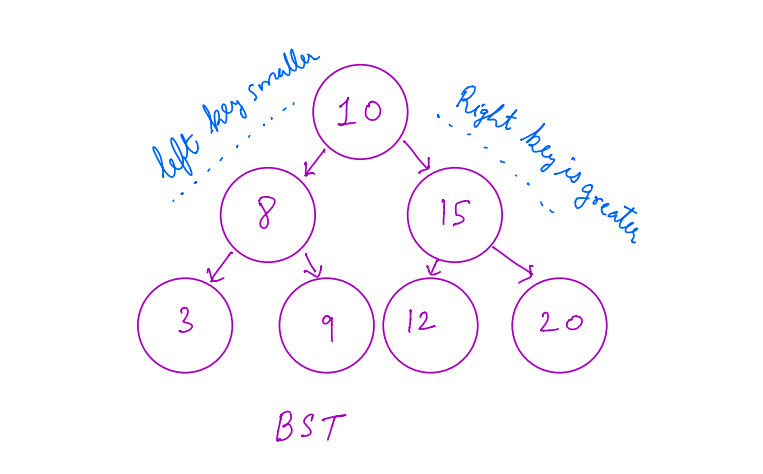
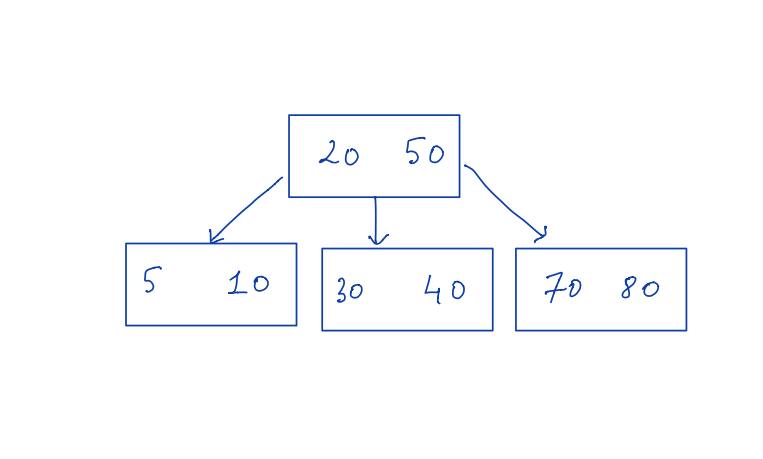
We can also say that BST is a 2-way search tree or a type of M-Way search tree.
Data representation of M-way search tree
Below is an example of how in terms of data structure each node of the M-way search tree could be represented. For simplicity, the diagram below shows a 4-Way search tree node representation.
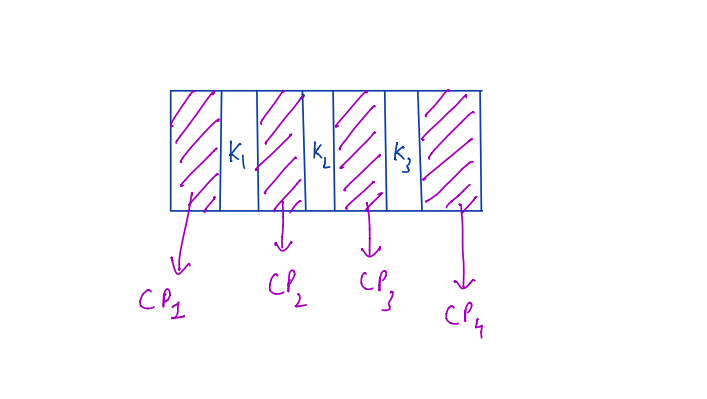
- Child Pointer
- Key-value
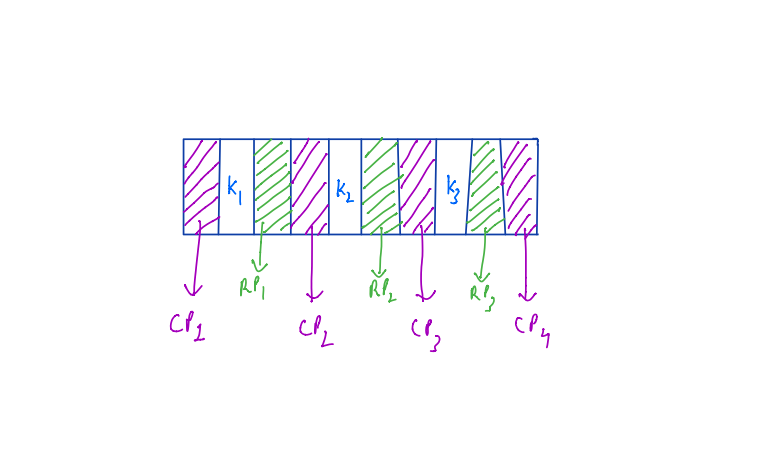
Since it’s a 4-way search tree there are 3 key values represented as K1, K2 and K3 plus 4 child pointers denoted as CP1, CP2, CP3, and CP4.
To make use of this M-Way search tree in the database we also have a record pointer associated with each Key. This record pointer points to the specific block of records in the database. The example diagram is shown below.
B Trees
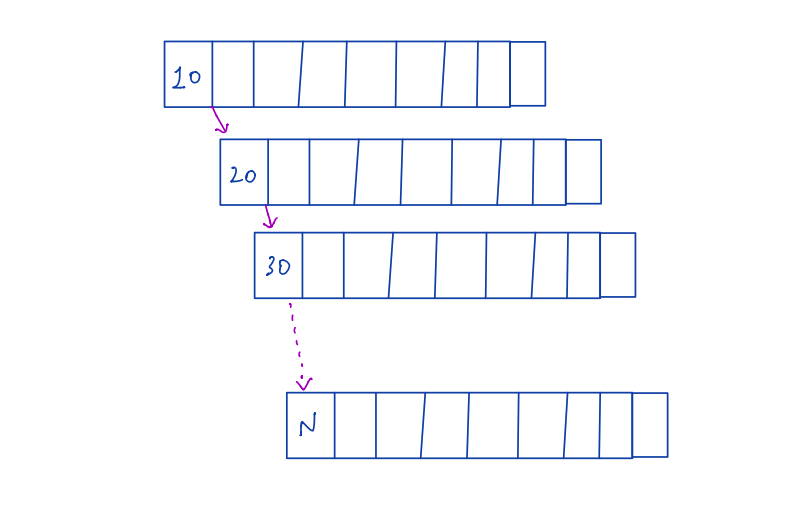
There is one problem with the M-Way search tree. The new node creation process does not have any specific rules defining it. Suppose it’s a 10-way search tree and we want to insert values such as 10,20,30,…,N.
We Could end up with a tree shown below. Which is still a valid 10-Way search tree.
Rules for creating B-Trees
- For every node except the root should have at least M/2 keys filled before creating a new node.
- The root can have a min of 2 children.
- All Leaf nodes should be at the same level.
- The creation process is bottom-up.
Thus we can say that B-trees are just M-Way search trees with additional rules defining the node creation process.
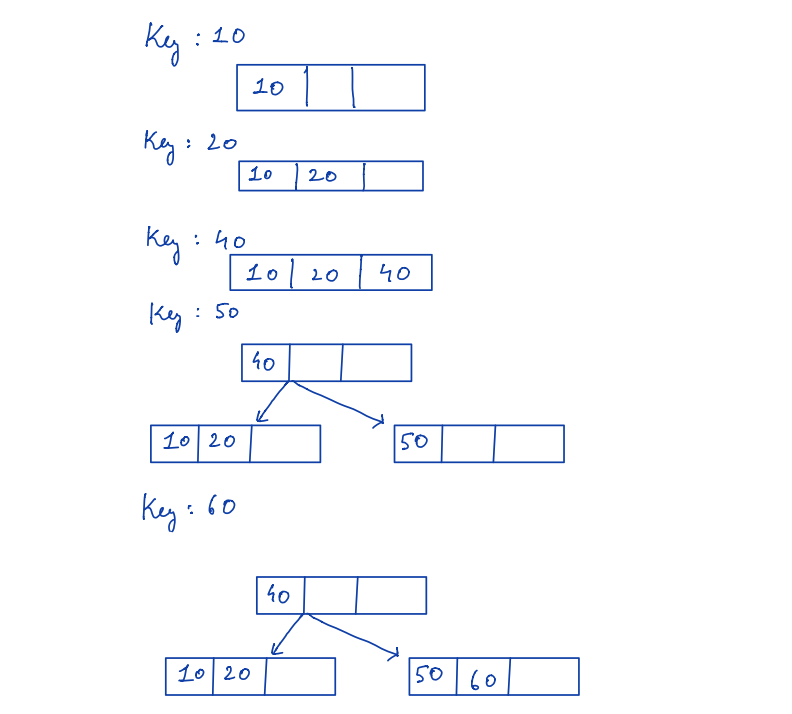
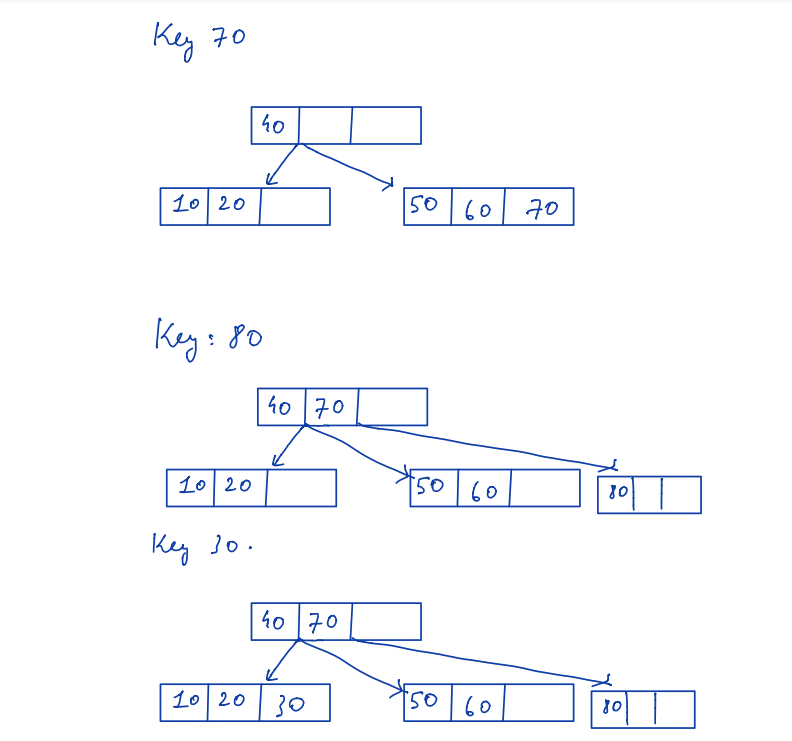
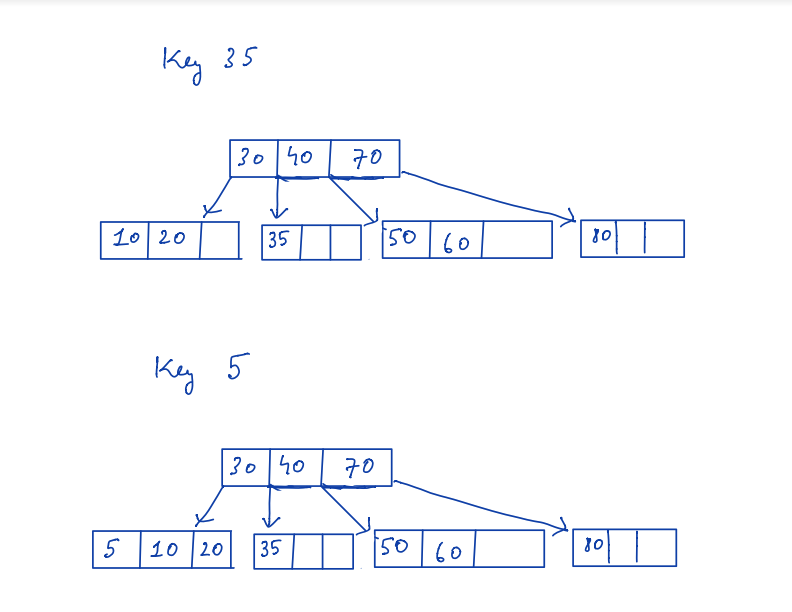
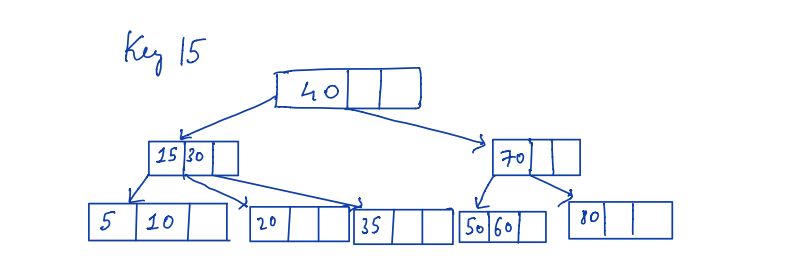
Let’s go through an example explaining how the B-tree is created step-by-step.
Suppose M = 4
Keys to insert = 10,20,40,50,60,70,80,30,35,15
Usually when the node becomes full then split the node an create a new node at the top. The following example shows the process of B-tree creation.
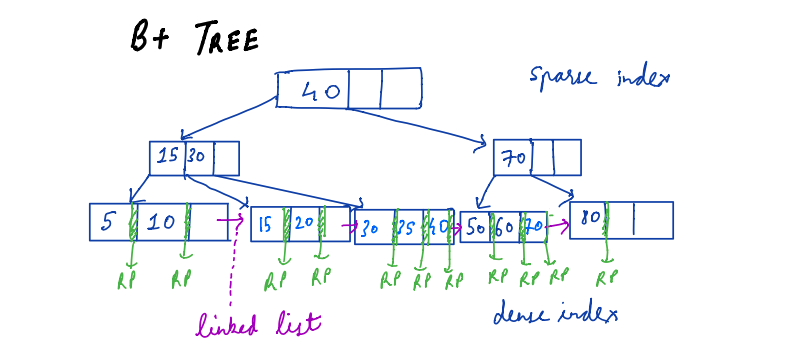
B+ Trees
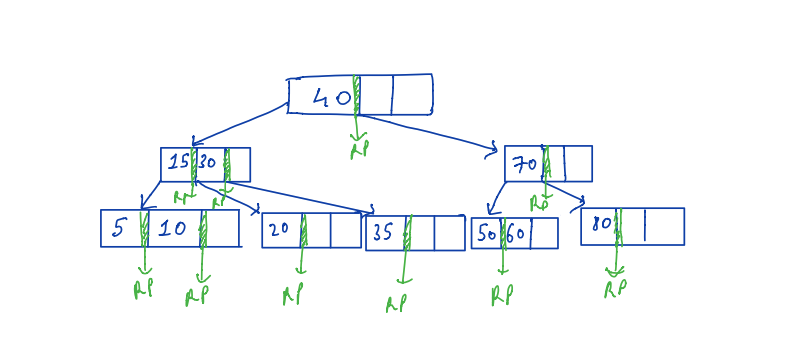
B+ tree is similar to the B tree with few modifications.
- Only the leaf node has the record pointer.
- Every key will be present in the leaf node.
- Leaf nodes are connected using a linked list.
The following figure shows the structure of B+ trees.