
Hadoop Ecosystem for Beginners

What is Hadoop
According to the Apache Hadoop official website
“The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.”
“The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.”
When we are getting large amount of data. Storing that kind on data into a single system can be difficult and also sometimes impossible. We can store that data on multiple distributed systems.
Hadoop provides a way to access this data as single file system and process large datasets on computer clusters. Hadoop is open source, it’s free!
Little history about Hadoop
Google published Google File System (GFS) 2003-2004 which inspired Hadoop storage. Map reduce inspired Hadoop distributed processing. Originally build by Yahoo. They was building Nutch, as open source web search engine.
Hadoop is named after a soft toy, it does not mean anything. It has been evolving since.

Why to use Hadoop?
When the data is too big and size of the company is increasing. Hence one PC is not going to work. We can’t scale any further. Even if we had one large database we have to deal with disk seek times and hardware failures.
Hadoop avoids single point of failure by using distributed system. Also provides horizontal scaling which is linear. Hadoop was originally made only for batch processing but it’s not limited to it any more.
Major components in Hadoop
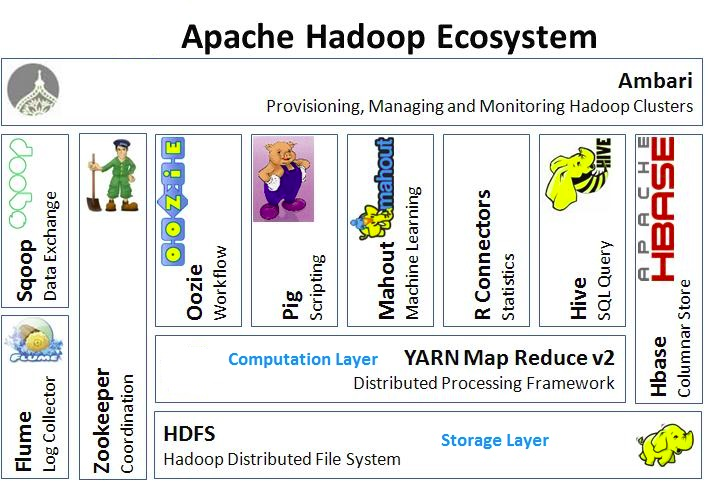
The above image may look little bit overwhelming. Let’s describe each component in short.
- HDFS: It stands for Hadoop Distributed File System. System that allows to distribute the storage of data across different system. Also makes redundant copy of the data. It is responsible for backup in case of single point of failure.
- YARN : It is the data processing part of Hadoop. System that manages the resources in the Hadoop. What nodes are available, how much memory to assign. Heartbeat to keep the system running.
- Map Reduce : Programming model to process the data in the entire clusters. It transform the data in parallel across different system and reducers aggregate the data in the end.
- PIG : It is a scripting language similar to sql style language. Programming API that looks more like SQL without writing python or java. High level scripting language that sits on top of map reduce.
- HIVE : It is similar to PIG. More similar to SQL. Look like sql database. If you are familiar with sql then it’s a useful api to use.
- Apache Ambari : It executes hive, pig queries. Sits on top of it and gives a view of the entire cluster. Cloudera, Horton Works,etc uses ambari.
- MESOS : It is similar to YARN(resource allocator)
- SPARK : Sits on top of YARN or MESOS. Write python, java, scala script. Very quickly and efficiently process data on Hadoop cluster. Do machine learning, streaming data, sql queries, etc.
- TEZ : similar to Spark.It is used mostly in conjunction to hive to speed up.
- HBASE : No sql database. Expose the data for large transaction exchange. Expose results to other system.
- Apache storm : processing streaming data in real time. Sensor, wearable, etc.
- OOZIE : It is a way of scheduling all the things into jobs. If the operation takes a longer time or is complicated then use Oozie for scheduling jobs.
- Zookeeper : It is used for coordinating., keeping track of shared states and clusters, maintain reliable performance. It also tracks who the current master node is and which node is up/down.
- Data Ingestion:
- Scoop : It is a connector between Hadoop and legacy database
- Flume : It is used for web logs that can be translated into the cluster in real time.
- EXTERNAL DATA STORAGE:
- MySQL
- Cassandra
- Mongo DB
0 Comments