
Learn And Create Your Movie Recommendation System Design

Introduction to the World of Movie Recommendation Systems
Recommendation systems have become a staple in our digital lives, offering personalized content tailored to our preferences. These systems are particularly prominent in the entertainment industry, where they guide users through vast collections of movies and TV shows.
In today’s fast-paced digital world, recommendation systems are not just convenient; they’re essential. They help users navigate an overwhelming array of choices, improving the overall user experience and engagement.
This comprehensive guide will delve into the intricacies of movie recommendation systems. We’ll explore their types, the underlying mathematics, and practical steps to design and code your system. Plus, we’ll look at real-world applications and case studies to solidify your understanding.
Discover the secrets of efficient system design in our blog: Master System Design Effortlessly.
Understanding the Basics of Recommendation Systems
What are Movie Recommendation Systems?
Recommendation systems are sophisticated algorithms that suggest items (like movies) to users based on various factors, including past behavior and similarities with other users. At their core, recommendation systems aim to predict and meet user preferences, enhancing their experience and engagement with a platform.
Types of Recommendation Systems
- Content-based Filtering: This method suggests items similar to those a user has liked in the past. It’s like a friend who knows your taste and recommends movies you’re likely to enjoy.
- Collaborative Filtering: This approach uses the preferences of many users to recommend items. Imagine a community where everyone shares their favorite movies; that’s collaborative filtering at work.
- Hybrid Models: These models blend both content-based and collaborative filtering to provide more accurate and diverse recommendations.
The Mathematics Behind Movie Recommendation Systems
Recommendation systems, particularly those in the realm of movies, leverage various mathematical concepts and equations to predict user preferences and suggest relevant content. Below, we delve into the key mathematical foundations that empower these systems.
Dive into the future of databases: B&B Trees: The Indexing Revolution.
Fundamental Concepts
1. Similarity Metrics:
- Cosine Similarity: This metric is used to measure the cosine of the angle between two non-zero vectors in a multi-dimensional space, providing an indication of how similar they are.
- Cosine Similarity(A, B) = (A · B) / (‖A‖ ‖B‖)
- Pearson Correlation Coefficient: Often used to measure the linear correlation between two variables, offering insights into the strength and direction of their relationship.
- ρₓ,ᵧ = cov(X, Y) / (σₓ σᵧ)

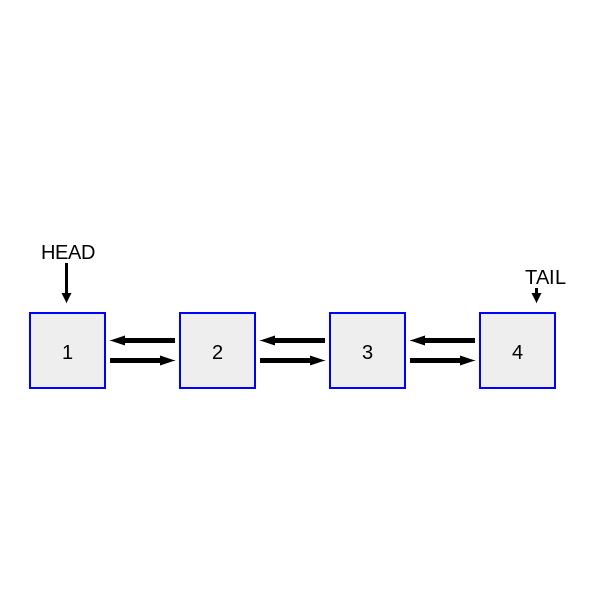
The third step would be to create some helper functions. Removing a node from the doubly linked list and Inserting the node in front o
The fourth step would be to support get operation. We check for the key in the hashmap. If the key is present call our helper methods remove node and add it to the front of the list. If the key is not present in the hashmap then we simply return -1.
2. Matrix Factorization:
- A technique used to decompose a matrix into a product of multiple matrices. It’s particularly useful in sparse matrices (like user-item matrices in recommendation systems).
- Singular Value Decomposition (SVD): One common form of matrix factorization in recommendation systems.
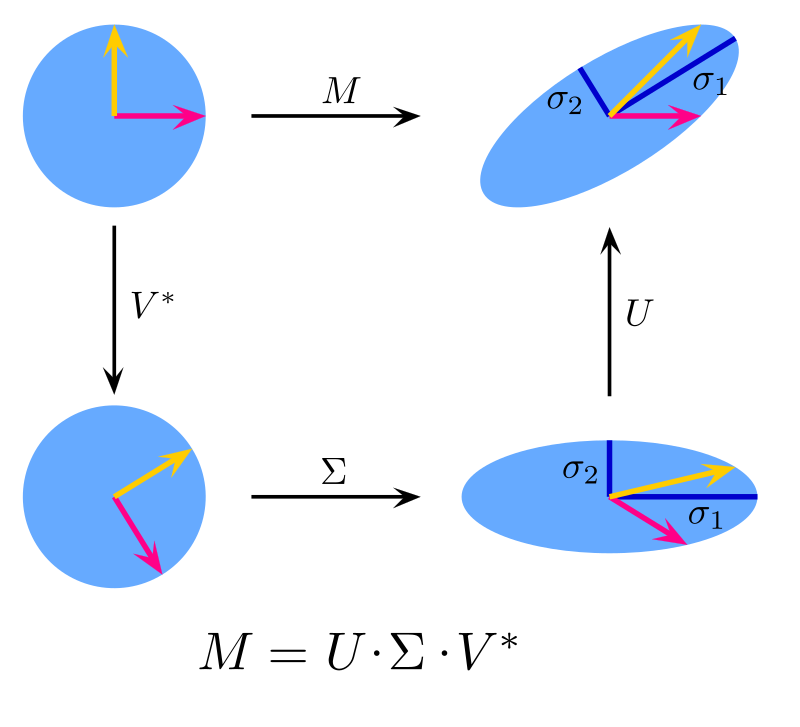
Matrix Factorization
3. Euclidean Distance:
Used in clustering algorithms (like K-Means) and measures the ‘distance’ between two points in Euclidean space.
d(p, q) = √((q₁ – p₁)² + (q₂ – p₂)² + … + (qₙ – pₙ)²)

Figure 5: Two-dimensional Euclidean distance. Source: https://commons.wikimedia.org/wiki/File:Euclidean_distance_2d.svg#/media/File:Euclidean_distance_2d.svg
Application in Recommendation Systems
User-Item Ratings Matrix:
A matrix where rows represent users and columns represent items (movies). The entries are the ratings given by users to movies. These matrices are often sparse, leading to the use of matrix factorization techniques for dimensionality reduction and pattern discovery.
Predicting Ratings:
Using matrix factorization techniques like SVD, the system predicts missing ratings in the user-item matrix, helping to recommend new items to users.
Finding Similar Users or Items:
Similarity metrics like cosine similarity and Pearson correlation are used to find users with similar tastes or items with similar characteristics. For example, if two users have similar ratings for a set of movies, they are likely to have similar tastes.
In summary, the mathematics behind movie recommendation systems is a blend of linear algebra, statistics, and machine learning. Understanding these concepts is crucial to designing effective and efficient recommendation algorithms. These mathematical tools allow systems to intelligently parse through vast datasets and offer personalized recommendations, enhancing user experience and engagement.
Excel in machine learning: LSTM Networks Demystified.
Designing Your Movie Recommendation System
Designing a movie recommendation system involves several critical steps, each playing a pivotal role in how effectively the system predicts user preferences and suggests movies. Here’s a detailed breakdown of the process:
1. Data Collection and Processing
Sources of Movie Data:
Databases like IMDb, TMDb, or MovieLens are excellent starting points. They provide comprehensive data, including movie titles, genres, user ratings, and more.
- Data Integrity: Ensure the data is complete and up-to-date. Missing or outdated information can lead to inaccurate recommendations.
Data Cleaning and Preprocessing:
Address missing values, remove duplicates, and handle anomalies in the data. Convert categorical data into a suitable format for analysis using techniques like one-hot encoding for genres.
2. Building the Recommendation Algorithm
Choosing the Right Algorithm:
Content-Based Filtering: Suggests movies similar to those a user likes. It analyzes item features like genre, director, or actors.
Collaborative Filtering: Makes recommendations based on the preferences of similar users. It’s effective in discovering new interests.
Hybrid Models: Combines both methods for more accurate recommendations.
Algorithm Development:
Model Training: Use a portion of your dataset to train the model. It’s important to tune parameters for optimal performance.
Validation and Testing: Use separate data subsets to validate and test the model’s accuracy and efficiency.
Scalability and User Preferences:
Ensure the system can handle a large number of users and movies. Scalability is key for real-world applications. For dynamic and personalized recommendations, incorporate user feedback loops like watch history and likes/dislikes.
3. Data Collection and Processing for Scalability
Handling Large Datasets:
Use efficient data structures and storage solutions to manage large volumes of data. Implement caching strategies and distributed computing if necessary.
Real-Time Processing:
For real-time recommendations, ensure the system can process data quickly and efficiently. Use streaming data processing technologies for up-to-date recommendations.
4. User Interface and Experience
Intuitive User Interface:
Design a user-friendly interface that makes it easy for users to find and explore movie recommendations. Incorporate features that allow users to provide feedback, like rating movies or indicating preferences.
Personalization:
Personalize the user experience based on individual preferences and interaction history. Continuously adapt recommendations based on user behavior.
5. Testing and Optimization
A/B Testing:
Conduct A/B testing to compare different versions of your recommendation system. Analyze user engagement and satisfaction to determine the most effective approach.
Performance Metrics:
Use metrics like click-through rates, conversion rates, and user retention to measure the system’s effectiveness. Regularly update the system based on these metrics and user feedback.
By following these steps and focusing on both technical and user-centric aspects, you can build a system that not only suggests relevant movies but also enhances the overall user experience. Remember, the key is to balance precision in recommendations with an engaging and intuitive interface.
Detailed Coding Walkthrough for a Movie Recommendation System
Now, we’ll dive into the practical steps of coding a movie recommendation system using Python. Our focus will be on a collaborative filtering approach, one of the most popular and effective methods in recommendation systems.
Step 1: Setting Up the Environment
Install Python: Ensure you have Python installed on your system. Python 3.x versions are preferred for better support and features.
Required Libraries: Install essential libraries such as Pandas for data manipulation, NumPy for numerical operations, and Scikit-learn for machine learning algorithms.
Python
pip install pandas numpy scikit-learn
Step 2: Data Collection
Choosing a Dataset: For our example, we’ll use the MovieLens dataset, which is a commonly used dataset in recommendation systems. It contains user ratings for various movies.
Loading Data: Use Pandas to load the dataset into a DataFrame. Ensure you have a clear understanding of the data’s structure (like user IDs, movie IDs, and ratings).
Python
import pandas as pd
ratings = pd.read_csv(‘ratings.csv’)
movies = pd.read_csv(‘movies.csv’)
Step 3: Preprocessing Data
Cleaning Data: Handle missing values and remove any duplicate entries.
Merging Dataframes: If your data is spread across multiple files (like ratings and movie titles), merge them for a comprehensive view.
Python
movie_data = ratings.merge(movies, on=’movieId’)
Step 4: Building the User-Item Matrix
Creating the Matrix: Convert the data into a user-item matrix where rows represent users, columns represent movies, and cells contain ratings.
Python
user_item_matrix = movie_data.pivot(index=’userId’, columns=’movieId’, values=’rating’).fillna(0)
Handling Sparsity: Recommendation datasets are typically sparse. Consider using matrix factorization techniques to handle this issue.
Step 5: Choosing and Training the Model
Model Selection: For collaborative filtering, a popular choice is the K-Nearest Neighbors (KNN) algorithm, which finds similar users based on movie ratings.
Training the Model: Fit your model to the user-item matrix. You may need to experiment with different parameters to find the best fit.
Python
from sklearn.neighbors import NearestNeighbors
model = NearestNeighbors(metric=’cosine’, algorithm=’brute’)
model.fit(user_item_matrix)
Step 6: Making Recommendations
Prediction Function: Write a function to input a movie title or user ID and output movie recommendations.
Interpreting Results: Understand and evaluate the recommendations. It’s crucial to ensure that they are sensible and relevant.
Python
def recommend_movies(movie_title, n_recommendations):
Function logic here
return recommendations
Unleash the potential of SQL: Must-Know SQL Indexing Techniques.
Tackling the Challenges Head-On
No innovation comes without its hurdles, and movie recommendation systems are no exception:
- The Newbie Dilemma (Cold Start Problem): When new users join, the system struggles to make spot-on recommendations. It’s like meeting a stranger and guessing their favorite movie genre. The trick? Asking the right questions upfront or using demographic data to make an educated guess.
- The Copycat Issue (Shilling Attack Problem): Like a wolf in sheep’s clothing, some users try to skew the system by faking ratings. It’s a game of digital cat and mouse, where the system needs to be the intelligent cat, quickly sniffing out these imposters.
- The Identity Crisis (Synonymy Problem): Sometimes, the system gets bamboozled by items that are essentially the same but go by different names. It’s like not realizing that “The Caped Crusader” and “The Dark Knight” are both Batman.
Spread the word on web development: Web Dev Tips for Web Development.
Conclusion: The Future of Movie Recommendation Systems
As we gaze into the not-so-distant future of movie recommendation systems, we’re standing at the precipice of a thrilling era in personalized entertainment. The journey ahead is dotted with innovations and challenges, each playing a pivotal role in shaping the next generation of these systems.
The future of movie recommendation systems is not just about more innovative algorithms or fancier tech; it’s about crafting experiences that resonate personally. It’s an ongoing quest to know what you might like and understand why you’d like it. As these systems evolve, they become less like machines and more like a friend who knows your movie tastes inside out.
Ultimately, it’s all about bringing you closer to that perfect movie match, making your movie-watching experience as delightful and unique as you are. The bright future promises a cinematic journey tailored just for you, one recommendation at a time.
Grasp the essentials of load balancing: Consistent Hashing Insights.